
Understanding indexes and how they work can be complicated enough for a Jr. DBA, but throw in all the different options and properties and an index can soon be overwhelming. In this post, I’ll discuss the different options available when creating a basic index.
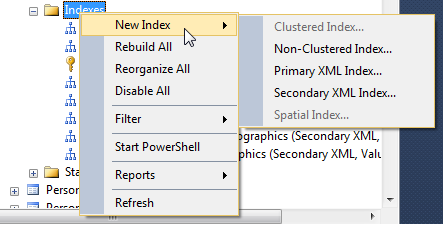
To create an index using SSMS, expand the tree for a table and right click on Indexes and select New Index: (This tip will not discuss the anatomy of an index, but will focus on the properties.)
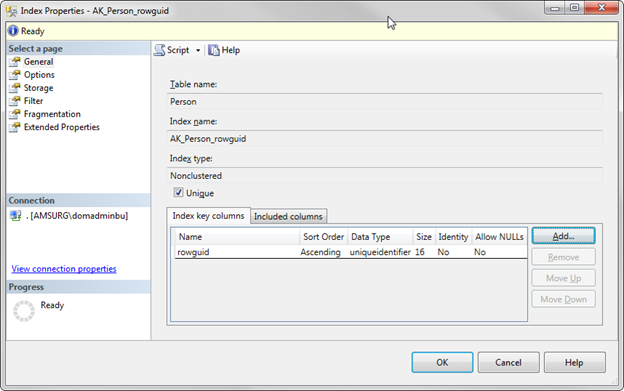
After choosing the index type, you will notice that there a few tabs on the left side that will define how your index will act. These tabs will differ between SSMS versions but basically have the same information. In this tip, we’ll be using SQL Server 2012 SSMS.
The first tab, General, is where you can set the index name, the key columns, and the included columns (if any). This tab also shows the table name and index type you selected:
The next tab, Options, is where you can view or modify the properties for the index:
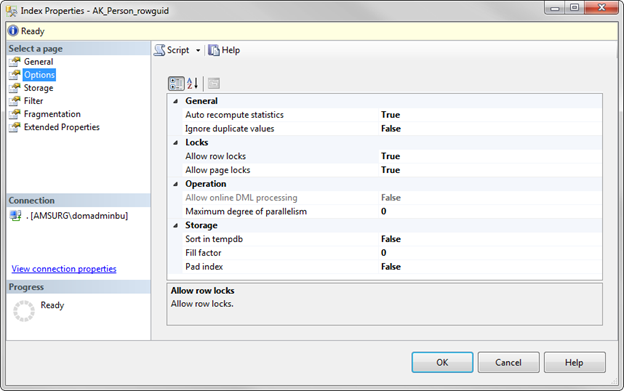
Let’s go over each property.
Index Properties Options Page
We will begin with the options page.
Auto recompute statistics
This property defines whether or not you want SQL Server to automatically update the index statistics. Best practice is to leave this option set to True, otherwise you will have to manually update the statistics.
According to Microsoft, statistics are considered outdated when the following happens:
- The table size has gone from 0 to >0 rows.
- The number of rows in the table when the statistics were gathered was 500 or less, and the column modification counters (colmodctr) of the leading column of the statistics object has changed by more than 500 since then.
- The table had more than 500 rows when the statistics were gathered, and the colmodctr of the leading column of the statistics object has changed by more than 500 + 20% of the number of rows in the table when the statistics were gathered.
Outdated statistics can lead to performance problems.
As the link above states, the statistics auto update is triggered by query optimization or by execution of a complied plan, and it involves only a subset of the columns referred to in the query.
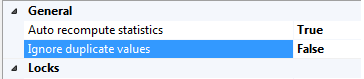
Ignore duplicate values
This property specifies where a duplicate key value can be inserted into the column that is part the index. If set to “True”, SQL Server will issue a warning when an INSERT statement is about to create a duplicate key and will ignore the duplicate row. If this option is set to “False”, SQL Server will issue an error message and rolls back the INSERT statement.
Example:
In this example (AdventureWorks2012.Person.Person), I have a Non-clustered, unique index. My key column is rowguid.
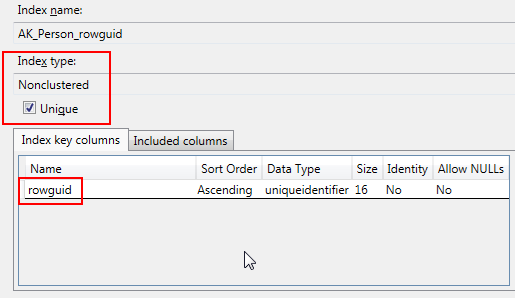
I’ve set the Ignore duplicate values to “False”
If I try to INSERT a duplicate value for rowguid, I get the following error:
If I change the Ignore duplicate values to “True” and try to INSERT a duplicate value for rowguid I get the following:
As you can see, neither of these inserted the duplicate value because it was a UNIQUE index but one returned an error message and ended the statement while the other didn’t return an error. If I was inserting multiple records the first message would have rolled back the transaction while the second message would have inserted all the unique values and skipped over the unique record.
The default value for this option is “False” and can only be used on UNIQUE indexes.