Azure SQL Database offers powerful PaaS capabilities, but it lacks the familiar SQL Agent you might rely on for index and statistics maintenance in traditional SQL Server. Fortunately, Elastic Jobs can help you fill this gap and keep your databases healthy.
In this post, I’ll walk you step-by-step through automating index and statistics maintenance across multiple Azure SQL Databases using Elastic Jobs.
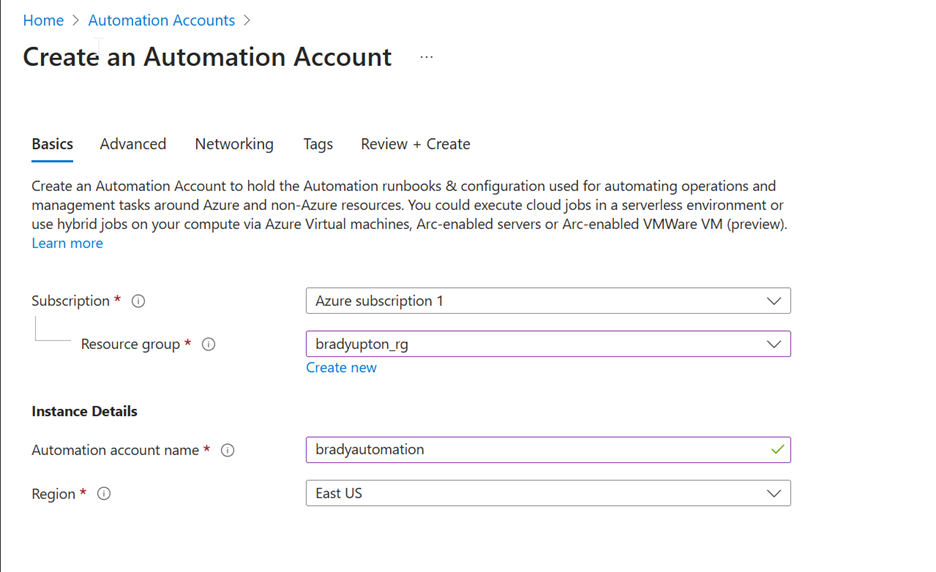
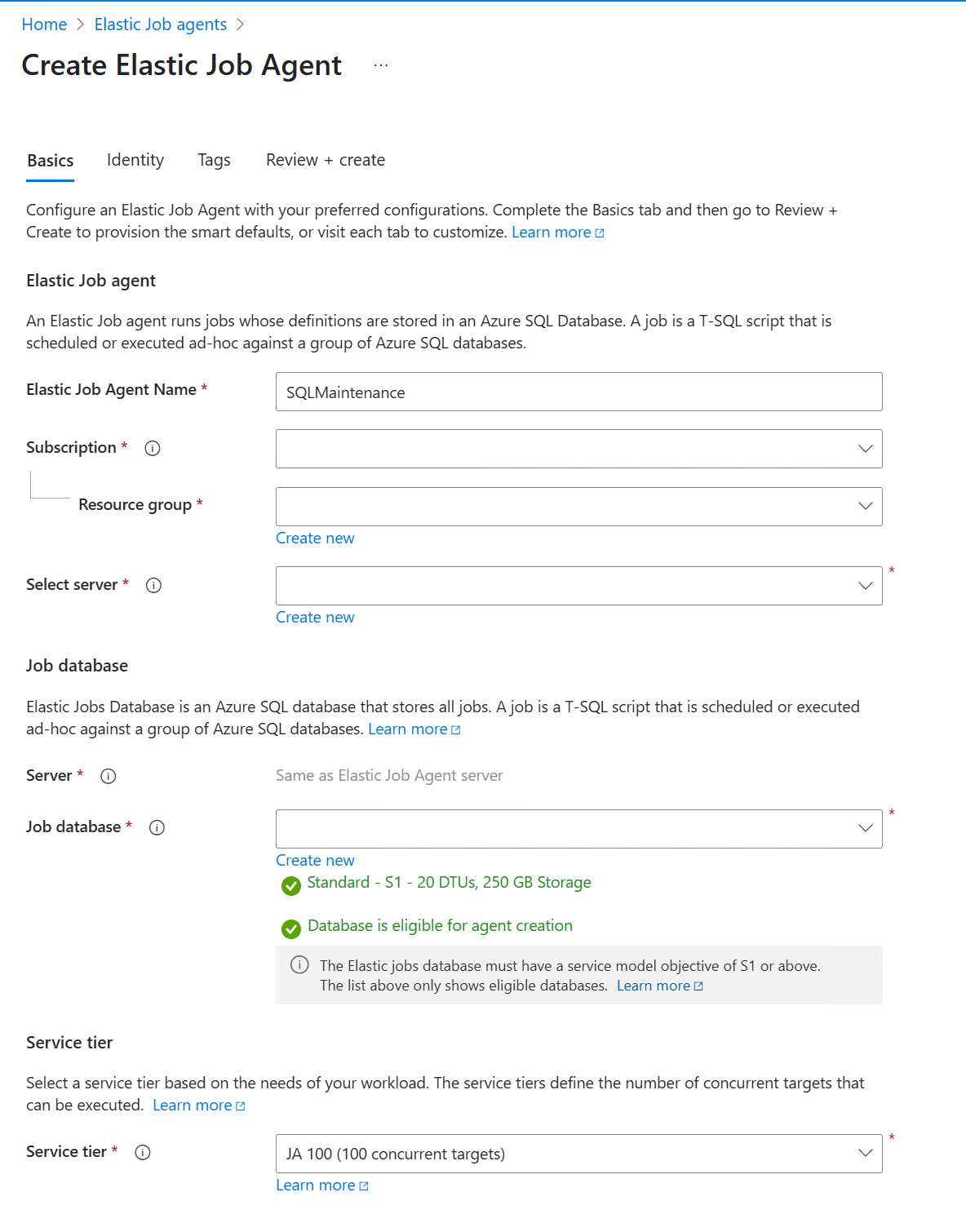
1. Create an Elastic Job Agent
In Azure Portal:
-
Search for Elastic Job Agents.
-
Click + Create.
-
Choose a Job Database (stores metadata and logs—don’t use your production DB).
-
Review and create.
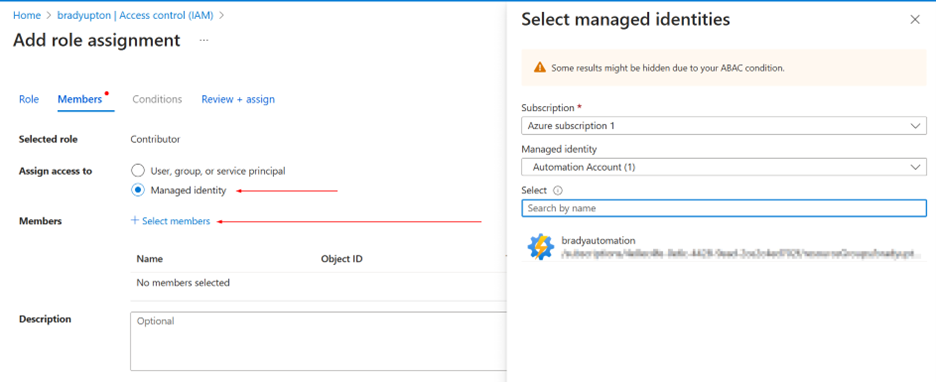
2. Configure Authentication
Elastic Jobs must authenticate to your target databases. You can:
- Use a Managed Identity (Recommended)
- Use SQL Authentication
For a managed identity:
-
Enable it on the Elastic Job Agent under Identity.
-
In each target database, create an external user:
CREATE USER [sqlfreelancer-job-agent-identity] FROM EXTERNAL PROVIDER;
ALTER ROLE db_owner ADD MEMBER [sqlfreelancer-job-agent-identity];
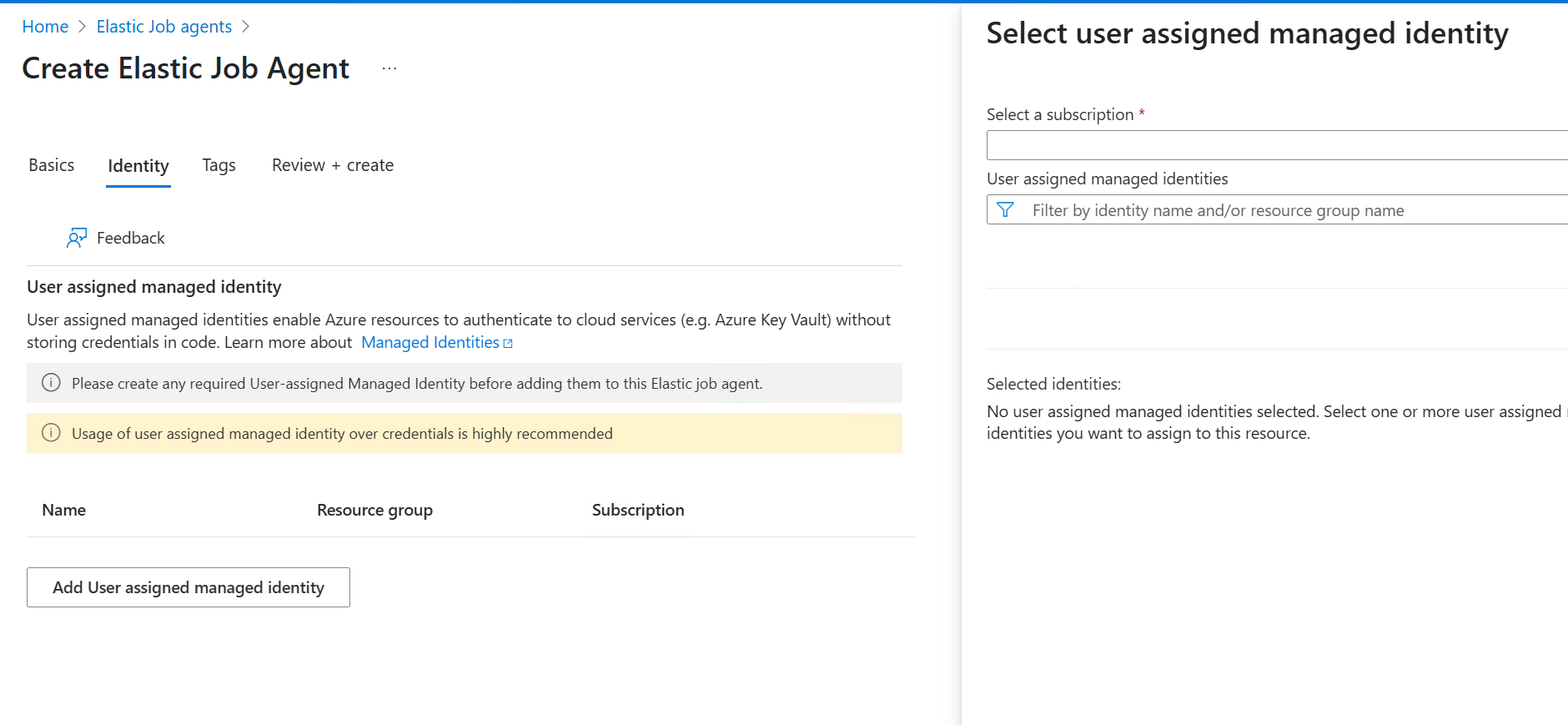
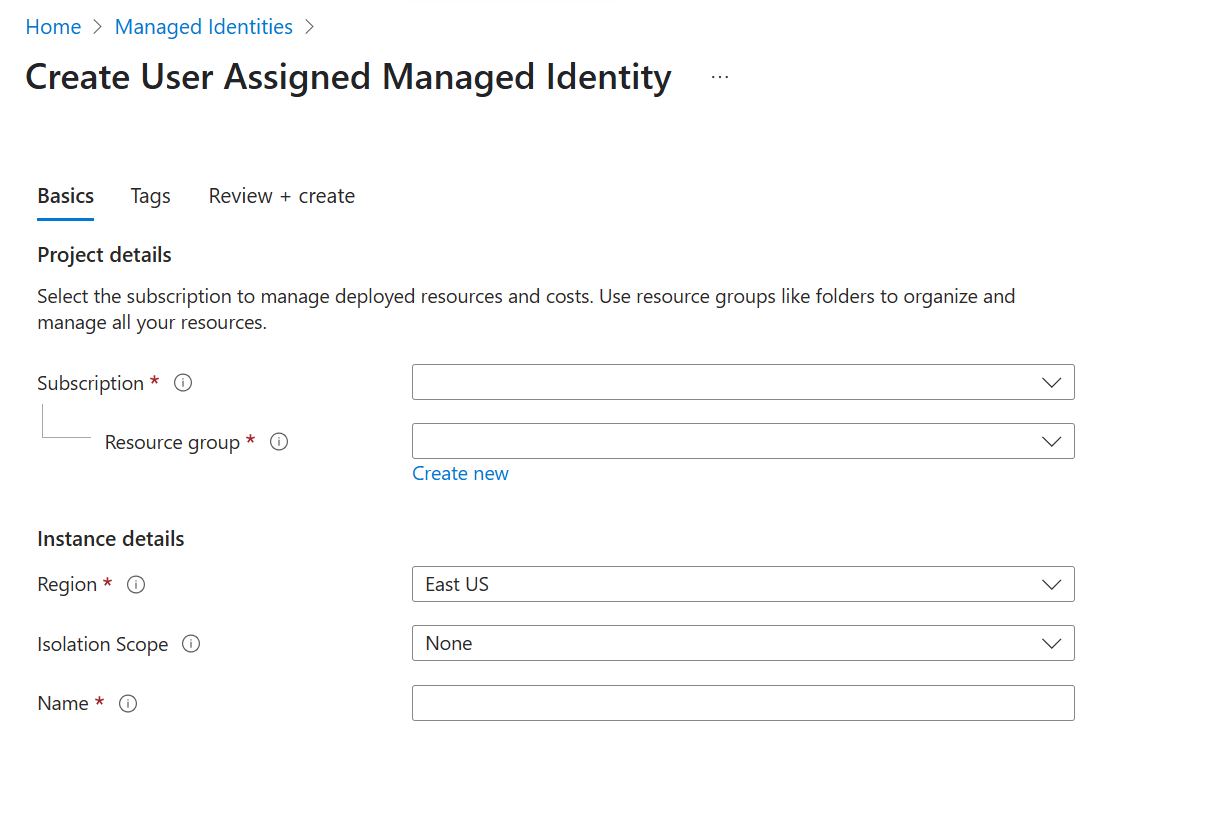
** To create a new Managed Identity (if necessary)
-
Go to Azure Portal > Managed Identities
-
Click + Create
-
Choose:
-
Region: Same as your Job Agent
-
Resource group: Same as your Job Agent
-
Name: e.g.,
sqlfreelancer-job-agent-identity
-
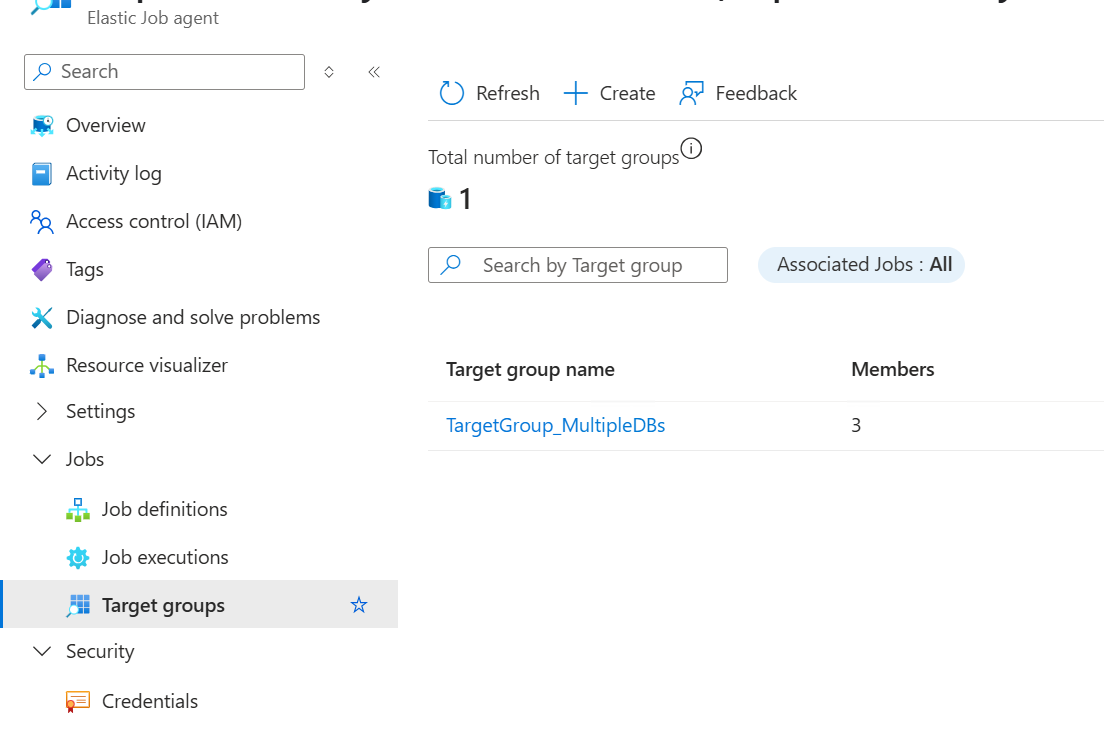
3. Create a Target Group
A target group defines the collection of databases or servers where a job will be executed It acts as a container, specifying the scope of the job’s execution.
Connect to your Job Database using SSMS:
Then add each database:
EXEC jobs.sp_add_target_group_member
@target_group_name = N'TargetGroup_MultipleDBs',
@target_type = N'SqlDatabase',
@server_name = N'your-server-name.database.windows.net',
@database_name = N'Database1';
EXEC jobs.sp_add_target_group_member
@target_group_name = N'TargetGroup_MultipleDBs',
@target_type = N'SqlDatabase',
@server_name = N'your-server-name.database.windows.net',
@database_name = N'Database2';
EXEC jobs.sp_add_target_group_member
@target_group_name = N'TargetGroup_MultipleDBs',
@target_type = N'SqlDatabase',
@server_name = N'your-server-name.database.windows.net',
@database_name = N'Database3';
4. Create the Job
EXEC jobs.sp_add_job @job_name = N'IndexAndStatsMaintenance_MultiDB';
5. Add the Job Step
Here’s an example T-SQL script to rebuild fragmented indexes and update statistics:
EXEC jobs.sp_add_jobstep
@job_name = N'IndexAndStatsMaintenance_MultiDB',
@step_name = N'RebuildIndexesAndUpdateStats',
@command = N'
DECLARE @TableName NVARCHAR(256),
@IndexName NVARCHAR(256),
@Frag FLOAT,
@SQL NVARCHAR(MAX);
DECLARE frag_cursor CURSOR FOR
SELECT s.name + ''.'' + o.name, i.name, ips.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, ''LIMITED'') ips
JOIN sys.indexes i ON ips.object_id = i.object_id AND ips.index_id = i.index_id
JOIN sys.objects o ON o.object_id = i.object_id
JOIN sys.schemas s ON s.schema_id = o.schema_id
WHERE ips.index_id > 0 AND ips.avg_fragmentation_in_percent > 5 AND o.type = ''U'';
OPEN frag_cursor;
FETCH NEXT FROM frag_cursor INTO @TableName, @IndexName, @Frag;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @Frag > 30
SET @SQL = N''ALTER INDEX ['' + @IndexName + ''] ON '' + @TableName + '' REBUILD'';
ELSE
SET @SQL = N''ALTER INDEX ['' + @IndexName + ''] ON '' + @TableName + '' REORGANIZE'';
EXEC sp_executesql @SQL;
FETCH NEXT FROM frag_cursor INTO @TableName, @IndexName, @Frag;
END
CLOSE frag_cursor;
DEALLOCATE frag_cursor;
EXEC sp_updatestats;
',
@target_group_name = N'TargetGroup_MultiDBs';
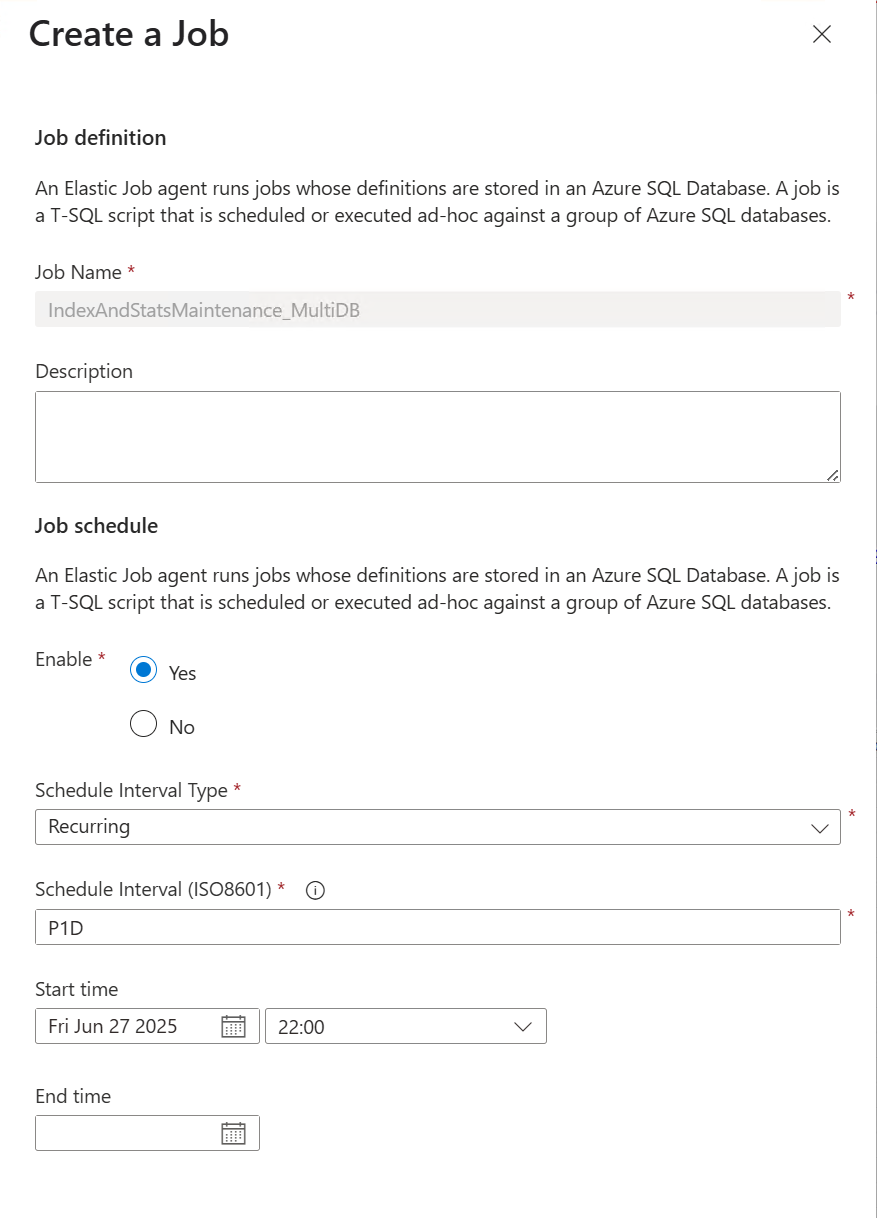
6. Schedule the Job
Unlike SQL Server Agent, Elastic Job schedules are created in Azure Portal:
-
Go to your Elastic Job Agent.
-
Select your job.
-
Click Job Definition.
- Select your job definition and click Edit.
-
Fill in:
-
Start Time (UTC): e.g.,
2024-06-22T02:00:00Z -
Recurrence (ISO8601):
-
Daily:
P1D -
Hourly:
PT1H -
Every 12 hours:
PT12H
-
Monitoring and Troubleshooting
Use these queries in your Job Database:
-
Recent Job Runs:
SELECT * FROM jobs.job_executions ORDER BY start_time DESC;
Elastic Jobs are a great way to automate maintenance in Azure SQL Databases without extra infrastructure. With a little setup, you can keep indexes and stats healthy—just like SQL Agent.