From Microsoft, the Balanced Data Distributor (BDD) transformation takes advantage of concurrent processing capability of modern CPUs. It distributes buffers of incoming rows uniformly across outputs on separate threads. By using separate threads for each output path, the BDD component improves the performance of an SSIS package on multi-core or multi-processor machines.
The Balanced Data Distributor transformation helps improve performance of a package in a scenario that satisfies the following conditions:
- There is large amount of data coming into the BDD transformation. If the data size is small and only one buffer can hold the data, there is no point in using the BDD transformation. If the data size is large and several buffers are required to hold the data, BDD can efficiently process buffers of data in parallel by using separate threads.
- The data can be read faster than the rest of the data flow can process it. In this scenario, the transformations that are performed on the data run slowly compared to the rate at which data is coming. If the bottleneck is at the destination, the destination must be parallelizable though.
- The data does not need to be ordered. For example, if the data needs to stay sorted, you should not split the data using the BDD transformation.
Let’s dive in and take a quick look at how the Balanced Data Distributor works.
Go ahead and open Visual Studio, it might take a minute to load.
We’re going to use AdventureWorks2019 database for this example. The SalesOrderDetail table has over 121k records so that’s a good candidate.
SELECT * FROM Sales.SalesOrderDetail
Now that we have data let’s go back over to Visual Studio and see if it’s still spinning.
Drag in a Data Flow task, double click to open and then let’s drag in an OLE DB Source and a Flat File Destination task.
I’m going to configure the source to point to my AdventureWorks2019 database and the destination to point to a .csv file on my local laptop.
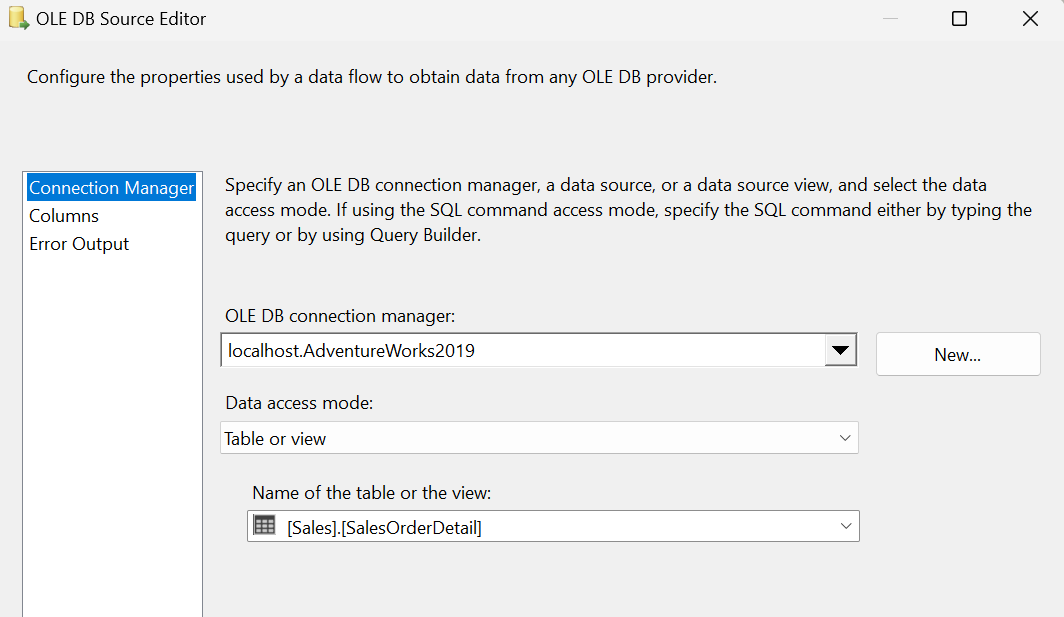
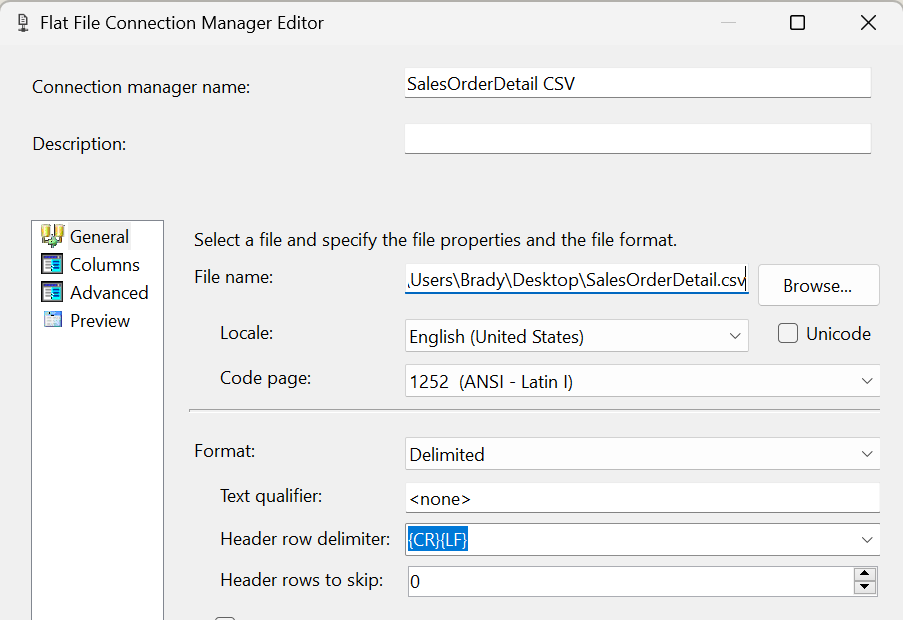
Easy enough. Let’s go ahead and run this and see what happens.
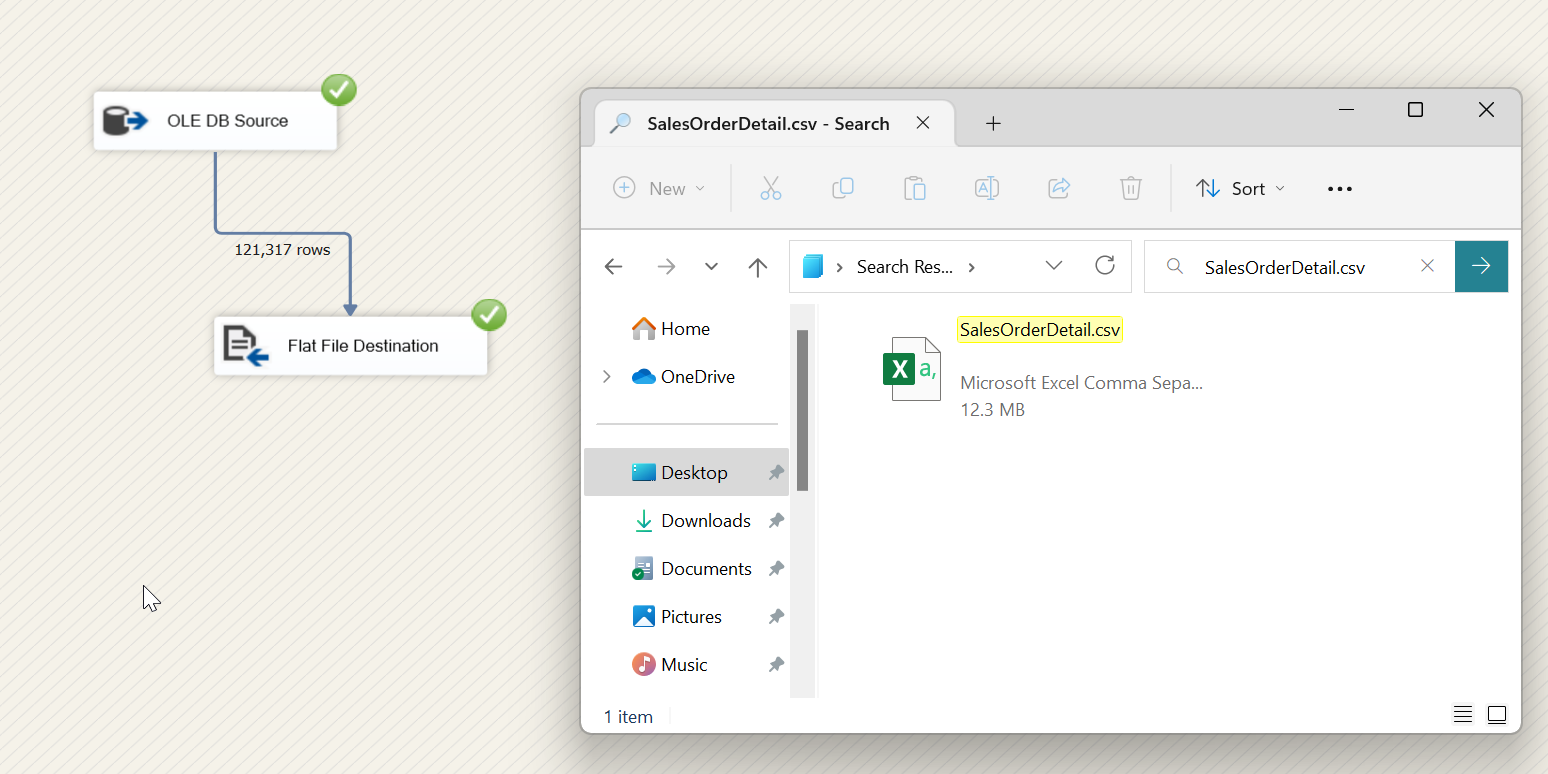
We can see that our 121k rows were written to our CSV file and the CSV file ended up being 12.3 MB. That’s pretty large for an email file attachment and might crash your laptop even trying to open this file. BDD not only offers performance benefits by using multiple threads, but it can also break up large files into smaller ones. IMO, this is what makes this task great.
We need to get this file down to less than 4MB so we’ll need to break this up 4 times. With that said, let’s add the BDD task between the source and destination tasks. There is nothing configurable *in* this task, however, there are some properties that may need to be tweaked. After adding the BDD task, we’ll need to add 3 more flat file destination tasks and 3 more flat file connection managers. End result should look something like this:
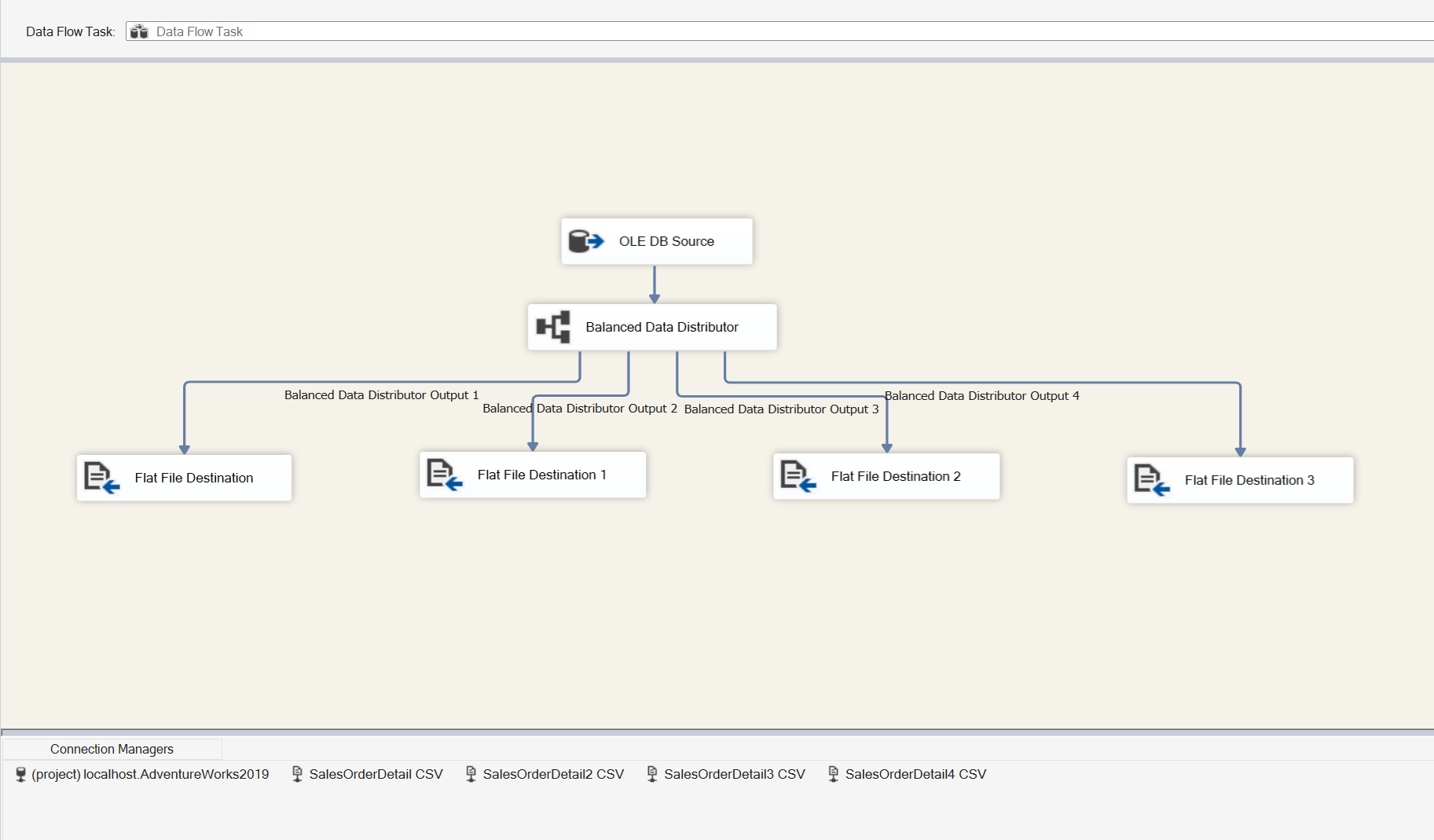
That’s really about it. Let’s fire it off and see the results of our flat files.
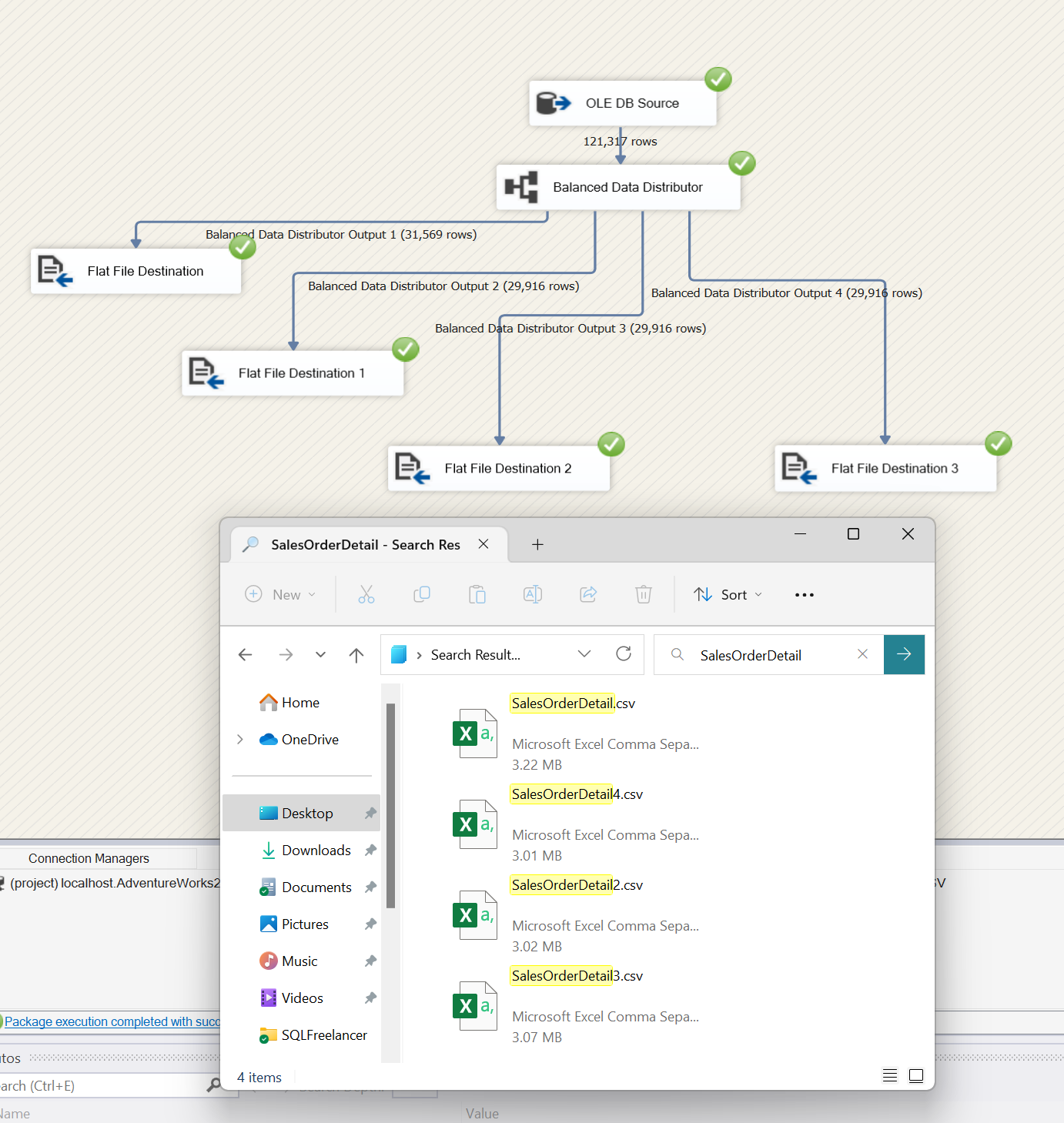
It worked! 121k rows were written across 4 flat files. Our flat file size is less than 4MB each and we can send these very easily via email. This is a very quick and easy way to split data between files, however, there is no order to these records so an ORDER BY is not helpful here. If the goal is to separate data by a category or condition then you’ll need to use a Conditional Split task which I wrote about in this post.